Qualquer estratégia digital que ignore o SEO técnico está construída sobre alicerces de areia. Enquanto produtores de conteúdo e profissionais de marketing frequentemente se concentram na densidade de palavras-chave e na aquisição de backlinks (SEO On-page e Off-page), a realidade inegável é que o melhor conteúdo do mundo é inútil se os motores de busca não conseguirem encontrá-lo, rastreá-lo e compreendê-lo.
O SEO técnico refere-se ao processo de otimização da infraestrutura de um site para permitir que os rastreadores dos mecanismos de pesquisa acessem e indexem suas páginas de forma eficiente. Diferente de outras vertentes do SEO, ele não lida com a promoção do site ou com a persuasão do texto, mas com a arquitetura de software, o desempenho do servidor e a conformidade com os rigorosos padrões técnicos exigidos por algoritmos modernos. Uma premissa comum, porém falha, é acreditar que o SEO técnico garante as primeiras posições. A verdade crua é: ele não garante rankings por si só, mas a falta dele garante o fracasso. Ele é o pré-requisito absoluto para a otimização de sites.

1. Fundamentos do Rastreamento e Indexação
Para entender o SEO técnico, é preciso pensar a partir dos primeiros princípios: como o Google interage com a web? O processo ocorre em três etapas fundamentais e sequenciais. Se houver uma falha técnica na primeira etapa, as subsequentes não ocorrerão.

1.1. O Processo de Discovery e Crawling
Tudo começa com a descoberta. O Googlebot (o rastreador web do Google) descobre novas URLs por meio de links em páginas já conhecidas ou através de sitemaps. O rastreamento (crawling) é o ato de baixar o código HTML e os recursos dessa página. Problemas de servidor (erros 5xx) ou restrições de firewall podem bloquear imediatamente este processo.
1.2. Renderização e Indexação
Historicamente, os motores de busca liam apenas o HTML estático. Hoje, eles precisam renderizar a página — executando o JavaScript e o CSS — para “ver” o site como um usuário humano veria. Após a renderização, os dados extraídos são armazenados no índice do Google. A indexação é o arquivamento dessa página em um banco de dados colossal. Se uma página não está indexada, ela literalmente não existe para o mecanismo de busca.
1.3. O Papel Crítico do Robots.txt e Sitemap XML
O controle desse fluxo é feito através de dois arquivos fundamentais:
- Robots.txt: Um arquivo de texto na raiz do domínio que dita as regras de engajamento para os rastreadores. Ele informa ao Googlebot quais seções do site não devem ser rastreadas. Um erro de sintaxe aqui pode desindexar um site inteiro da noite para o dia.
- Sitemap XML: Um arquivo que lista todas as URLs importantes que você deseja que os motores de busca encontrem. Um bom sitemap XML atua como um mapa rodoviário, acelerando a descoberta de páginas profundas ou recém-criadas.
2. Arquitetura do Site e Estrutura de URLs
A forma como as páginas de um site estão conectadas entre si define a sua arquitetura do site. Uma estrutura lógica não apenas beneficia a experiência do usuário (UX), mas otimiza a forma como a autoridade de link (o link equity ou PageRank) flui através do domínio.
2.1. Arquitetura Plana vs. Profunda
Uma arquitetura eficiente deve ser o mais “plana” possível. A regra de ouro rigorosa é: qualquer página do seu site deve ser acessível em no máximo três ou quatro cliques a partir da página inicial.
- Arquiteturas Profundas: Exigem muitos cliques para chegar ao conteúdo final. Os rastreadores frequentemente abandonam a busca antes de chegar às páginas profundas, resultando em páginas órfãs ou não indexadas.
- Arquiteturas Planas: Utilizam categorias claras e paginação inteligente, garantindo que o valor dos links da home page seja distribuído de forma eficiente para as páginas de produtos ou artigos.
2.2. Semântica de URLs
URLs devem ser fáceis de ler, descritivas e estruturadas logicamente. Elas são um fator de ranqueamento leve, mas um forte sinal de contexto.
- Evite:
[www.exemplo.com/p=123?sessionid=abc](https://www.exemplo.com/p=123?sessionid=abc) - Prefira:
[www.exemplo.com/categoria/nome-do-produto](https://www.exemplo.com/categoria/nome-do-produto)
3. Desempenho e Velocidade da Página: Os Core Web Vitals
A velocidade da página deixou de ser apenas um aspecto de usabilidade para se tornar um critério técnico rigoroso de ranqueamento. O Google mensura a experiência do usuário através de um conjunto de métricas chamado Core Web Vitals. Subestimar essas métricas é um erro estratégico grave.

3.1. Dissecando as Métricas
Os Core Web Vitals são compostos por três pilares principais que avaliam o carregamento, a interatividade e a estabilidade visual. A tabela abaixo resume as expectativas técnicas para cada métrica:
| Métrica de Desempenho | O Que Mede? (Foco) | Desempenho Ideal (Bom) | Precisa de Melhoria | Desempenho Ruim |
| LCP (Largest Contentful Paint) | Tempo de Carregamento do elemento principal da tela. | Menos de 2.5 segundos | 2.5s a 4.0s | Mais de 4.0s |
| INP (Interaction to Next Paint) | Responsividade e latência da interatividade geral. | Menos de 200 milissegundos | 200ms a 500ms | Mais de 500ms |
| CLS (Cumulative Layout Shift) | Estabilidade visual (mudanças de layout inesperadas). | Menos de 0.1 | 0.1 a 0.25 | Mais de 0.25 |
3.2. Como Otimizar o Desempenho
Atingir a faixa “Verde” na tabela acima requer otimizações em nível de servidor e de código frontal. As táticas baseadas em evidências incluem:
- Implementação de CDN (Content Delivery Network): Reduz a latência física servindo o site de servidores geograficamente próximos ao usuário.
- Minificação de CSS, JavaScript e HTML: Remoção de espaços, vírgulas desnecessárias e comentários do código-fonte.
- Otimização de Imagens: Utilização de formatos modernos (como WebP ou AVIF) e implementação de lazy loading (carregamento preguiçoso) para imagens fora da tela inicial.
- Gerenciamento de Caches: Configuração agressiva de cache de navegador e cache em nível de servidor (como Redis ou Memcached).
4. O Paradigma Mobile-First Indexing
Em um passado não muito distante, o Google usava a versão desktop do conteúdo de uma página para avaliar sua relevância. Hoje, o sistema funciona primariamente sob o paradigma do mobile-first indexing. Isso significa que o Google usa a versão móvel do site para rastreamento e indexação. Se o seu site não é funcional em smartphones, ele fracassará nos resultados de busca, independentemente da qualidade da versão desktop.
O design responsivo (usar a mesma base de código HTML/CSS para todos os dispositivos e adaptar o layout via media queries) é a abordagem tecnicamente superior e endossada pelo Google, eliminando os riscos associados ao gerenciamento de URLs separadas (como os antigos subdomínios “m.”).
5. Arquitetura de Segurança: HTTPS e Certificados SSL
A segurança é um fator fundamental de confiança. Sites que operam sob o protocolo HTTP enviam dados em texto simples, vulneráveis a interceptações. O SEO técnico exige a migração obrigatória para HTTPS por meio da instalação de um certificado SSL (Secure Sockets Layer).
O HTTPS criptografa a conexão entre o navegador do usuário e o servidor. O Google confirmou o HTTPS como um sinal de ranqueamento de desempate. Mais criticamente, navegadores modernos exibem avisos de “Não Seguro” em sites HTTP, o que afeta drasticamente a taxa de rejeição e prejudica indiretamente o SEO. Um cuidado técnico essencial durante esta implementação é garantir que todos os recursos internos (imagens, scripts, folhas de estilo) também sejam carregados via HTTPS para evitar erros de mixed content (conteúdo misto).
6. O Desafio do Conteúdo Duplicado e as Tags Canonical
Muitos sistemas de gerenciamento de conteúdo (CMS) criam inadvertidamente múltiplas URLs que apontam para a mesma página. Por exemplo, uma mesma camisa em um e-commerce pode ser acessada por URLs com parâmetros diferentes de cor ou tamanho. Isso gera conteúdo duplicado.
O perigo do conteúdo duplicado é a diluição da autoridade de ranqueamento. O mecanismo de busca fica confuso sobre qual versão indexar e acaba dividindo o peso dos backlinks entre as várias versões.
6.1. A Solução: Tag Canonical
A ferramenta técnica definitiva para resolver isso é a tag canonical (<link rel="canonical" href="..." />). Ela é inserida na seção <head> do HTML. Ao usar esta tag, o desenvolvedor instrui explicitamente o motor de busca: “Existem várias versões desta página, mas esta URL específica é a versão principal, ou ‘canônica’, que deve ser indexada e receber todo o valor de SEO”. O uso incorreto de canonicals — como apontar para páginas que retornam erro 404, ou criar loops canônicos — pode destruir o tráfego orgânico de um domínio.
7. Comunicação Direta: Dados Estruturados e Schema Markup
Os motores de busca são limitados em sua capacidade de inferir o contexto exato de certos tipos de informações em uma página. Para compensar essa limitação semântica, o SEO técnico utiliza os dados estruturados, frequentemente baseados no vocabulário do Schema.org.
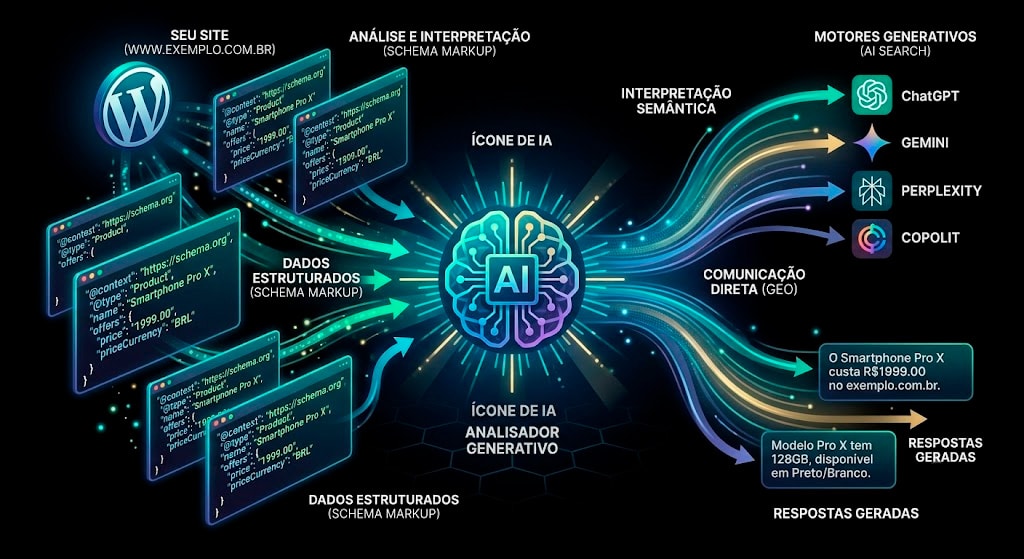
A implementação de marcações em JSON-LD no código-fonte ajuda o Google a classificar entidades específicas. Você pode dizer ao algoritmo: “Estes números representam o preço de um produto”, ou “Este texto é a avaliação de um cliente”. A vantagem pragmática de fornecer dados estruturados é a qualificação para os Rich Results (Resultados Ricos), que exibem estrelas, preços, imagens e FAQs diretamente na página de resultados, aumentando estatisticamente a Taxa de Clique (CTR).
8. SEO Internacional e Eficiência de Rastreamento
Para operações complexas, o SEO técnico envolve a manipulação da eficiência sistêmica e a correta sinalização geográfica e linguística.
8.1. A Importância da Tag Hreflang
Se você opera em múltiplos países ou idiomas, deve implementar as tags hreflang. Elas são atributos técnicos que indicam aos motores de busca a relação linguística e geográfica entre páginas alternativas. Isso evita que a versão em português do Brasil concorra diretamente com a versão em português de Portugal, servindo a página correta ao usuário correto com base em sua localização e idioma do navegador.
8.2. Otimização do Crawl Budget (Orçamento de Rastreamento)
O Google não possui recursos infinitos. Ele atribui um limite de tempo e processamento para rastrear seu site, conhecido como Crawl Budget. Para sites de grande porte (com milhões de URLs), desperdiçar o orçamento de rastreamento em páginas inúteis, categorias filtradas infinitas (faceted navigation) ou URLs de redirecionamento em cadeia significa que as páginas novas e importantes não serão descobertas. A governança técnica rigorosa, eliminando gargalos e páginas de baixo valor, é vital para manter a saúde do índice em grandes portais.
Conclusão
O SEO técnico não é um conjunto de tarefas que você executa uma vez e esquece; é a manutenção contínua e rigorosa da infraestrutura do seu negócio digital. Ele atua como o alicerce silencioso que permite que suas campanhas de conteúdo, relações públicas digitais e marketing de conversão alcancem seu potencial máximo. Ignorar o tempo de carregamento de uma página, a estrutura de renderização do JavaScript ou a gestão do estado das URLs é adotar uma postura de risco que invariavelmente levará à perda de tráfego orgânico. O próximo passo lógico após a compreensão destes conceitos é executar uma auditoria técnica profunda e sistemática em seu próprio domínio, priorizando problemas que bloqueiam o rastreamento ou prejudicam diretamente a estabilidade das métricas essenciais.